Fri, 04 Dec 2015
How this website gets published
In case you're interested, here are the technical details on how this website gets published.
- On my laptop, there's a directory, ~/projects/asheesh.org.
- It contains a git clone of a private git repository. That private git repository is hosted on my personal server, rose.makesad.us.
- I run a git hosting app called Gogs, using a web app package manager called Sandstorm, on my server which runs Debian GNU/Linux.
- Inside ~/projects/asheesh.org there is a directory called entries. Inside that, you'll find entries/note.
- I create a file called entries/note/software/this-site.mw which contains the content of this blog post, in MediaWiki markup format, because when I first put this publishing system together, I was hopeful that MediaWiki markup format would win against Markdown. (I lost that battle.)
- I commit that file to git.
- I run make update-snapshot on my laptop, which uses Pyblosxom (a 2004-era static site publishing system that I'm happy to say is still being maintained) to convert the various Markdown files and template files into HTML. Pyblosxom uses the file's mtime on disk to generate the datestamp that you see, so I use a tool called git-set-mtime to automatically use the last git commit time as the file's mtime on disk.
- I run make deploy which uses the owncloudcmd program to push the static site content to a directory on rose.makesad.us. Specifically, it synchronizes to an instance of another app in my Sandstorm setup called Davros.
- Davros is shockingly convenient, because it contains the ability to receive files via owncloudcmd _and_ it has the ability to serve them out to the world. For this, it relies on the help of Sandstorm and Sandstorm's static publishing API.
- So when a request comes in, it hits nginx running in the Debian-ish world on my server, and nginx knows that for the asheesh.org host, to send the request to the Sandstorm service running on localhost:6080. Sandstorm then looks at the inbound request, notices it's for asheesh.org, and does a DNS lookup check to find out which _grain_ (the Sandstorm term for app instance) is responsible for serving static content for asheesh.org, finds the Davros grain, and then serves the HTML that Davros registerd with Sandstorm via the static publishing API.
- Savvy systems-minded people will appreciate that the Davros code isn't on the critical path for serving a web page.
That's a large collection of things, but I like how they fit together. And, moreover, the fact that you can see this content means that the whole pipeline is working!
[] permanent link and comments
Sat, 02 Nov 2013
Censored on Facebook
For the first time in what feels like years, I wanted to share something with my friends on Facebook.
The background was that I read a note on Slashdot that Linus Torvalds thought a presidential candidate's remarks on a topic related to airline security were "moron"ic. So I did my own research, and I disagreed. I figured this was a topic of general enough interest that all my Facebook friends might be interested in knowing my position, so I wanted to share that.
Facebook didn't let me.
I tried first with a link to snopes.com, which blocked me with the rationale that http://snopes.com/images/template/snopes.gif is "spammy or unsafe":
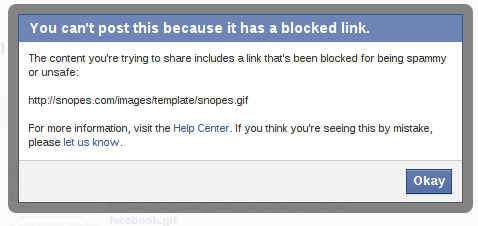
Then I thought I'd be clever, and I linked to the .nyud.net version of the snopes page on the topic. I earned the same message that my post included a blocked link.
So then I tried again, with a link to a video on YouTube of the same clip.
That's when I first got the extremely generic message that "The message could not be posted to this Wall." You can see the animation of what happened next by hovering below.
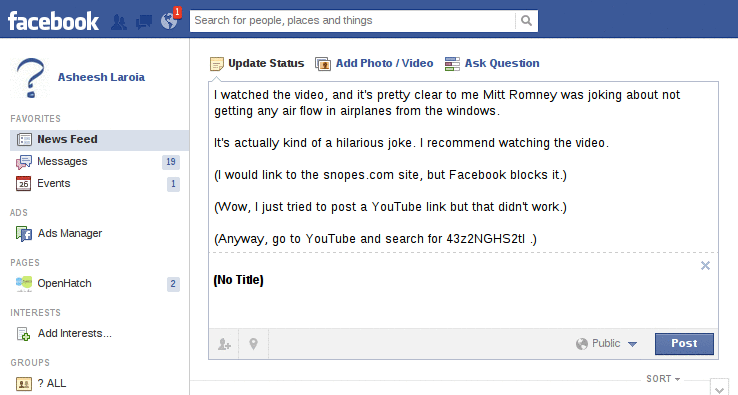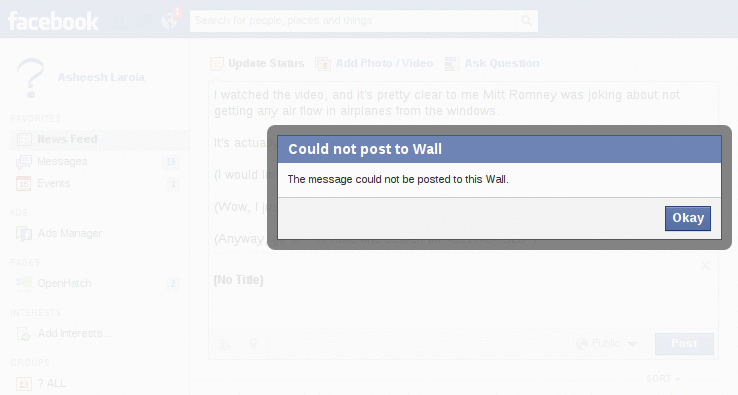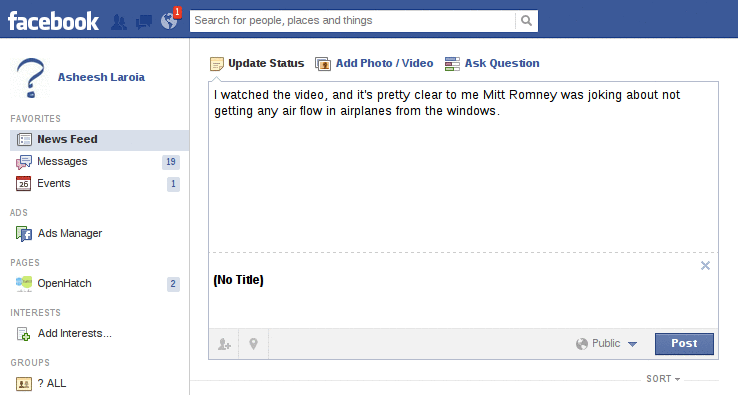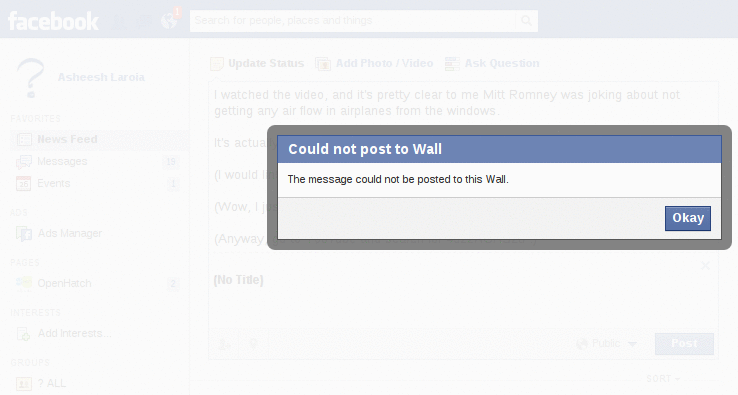
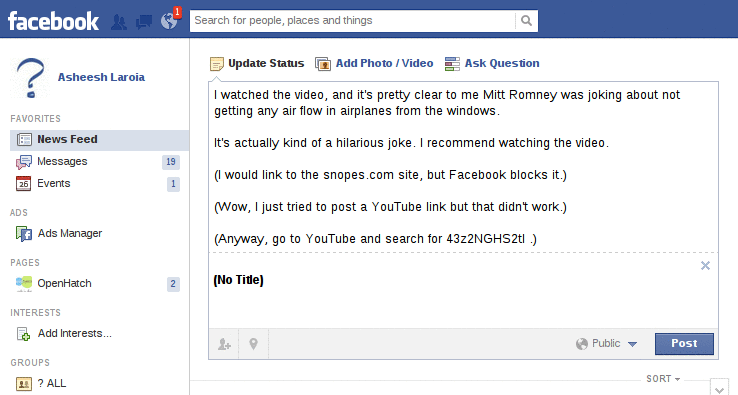
Finally, I removed all the links, and kept the first bit of text. For this, I got the same generic error: "The message could not be posted to this Wall."
Update: Patrick points out I should link to the actual video. Here it is, embedded:
(BTW: The first thing I did was to click "let us know" to indicate that I think I'm seeing this by mistake. I filled out the form to indicate there was a problem in an honest, respectful way. I got back an email autoresponse that said, "Thanks for taking the time to submit this report. While we don't currently provide individual support for this issue, this information will help us identify bugs on our site.")
[] permanent link and comments
Tue, 11 Jun 2013
De-spammed this blog (with Naive Bayes)
This morning, I was trying to decrease the amount of email in my inbox. I had a few messages with subjects like:
- comment on http://www.asheesh.org/note/debian/freed-software
- comment on http://www.asheesh.org/note/sysop/comments
- comment on http://www.asheesh.org/note/debian/freed-software
But all the comments in this case were spam. I'm using an Akismet API plugin for pyblosxom, but that has a few shortcomings. Like anything else, it misses some spam, but moreover, it doesn't help me find and remove old spam comments in bulk.
My pattern with email is basically to ignore it for a while, and then deal with it in bulk, sometimes missing messages from the past. The result is that I have often missed these comment notifications, and it was a bit of a drag to figure out which comments I had dealt with already.
So I wrote a small tool this morning. Here is how it works:
- It loops over the comments directory.
- A script reads each comment and prints it to standard out in mailbox format, piping the message to spambayes for processing.
- The main script shows me spambayes' guess as to if the message is spam, as well as spambayes' certainty, and asks me to confirm. If I confirm it is spam, it asks if I want to delete it. (If it notices spambayes got it wrong, it retrains spambayes.)
- After I have dealt with the comment, it creates a stamp file next to the comment so that it won't ask me about that the next time I run the tool.
Voila! A spam moderation queue with artificial intelligence.
You can find it here, on my Github account: https://github.com/paulproteus/spambayes-pyblosxom
Permission to re-use the code is granted under the terms of CC Zero or Apache License 2.0, at your option.
Moreover, now I believe there are zero spam comments left lying around this blog!
[] permanent link and comments
Fri, 08 Feb 2013
Notes from attempting to despam a wiki with git-remote-mediawiki
I just tried to despam a mediawiki instance with git-remote-mediawiki.
The idea is as follows:
- Use git-remote-mediawiki to clone the wiki into a local git repo.
- Make a list of bad users, either by skimming Special:RecentChanges, or by some other more automated means. For example, use 'git log' to get everyone since the last time you felt the wiki was clean:
git log --since='Wed Dec 5 22:57:06 2012 +0000'
(You can process that with either 'grep ^Author' and so on, or you can use an overwrought Python script I wrote.)
- Get a list of their commits:
git log --author=bad_user_1 --author=bad_user_2 --pretty="format:%H"
Here's where things start to go wrong.
You might try to revert them all:
git log --author=bad_user_1 --author=bad_user_2 --pretty="format:%H" | xargs -n1 git revert
That works great until the first merge conflict.
So then you write a wrapper script that does "git revert $1 || git revert --abort", and you can still only revert the first few hundred (out of ~800) spam edits because one of the commits causes a conflict when you try to revert it.
Why a conflict? I suspect it's because there are spam edits that I neglected to include in the revert stream. (Update: The conflict was actually a real conflict -- some kind soul on the web had already reverted a bunch of the spam edits!)
In our case, there are fairly few pages getting spammed, so it'd be simpler to 'git log' the pages we care about and revert back to the commit IDs that look clean. 'git revert' could still be useful in the case of tangled history, but (apparently) there is a limit to how useful it can be, anyway.
Oh, also:
It'd be useful to be able to create MediaWiki dump files from git-remote-mediawiki exports. That way, I could use 'git rebase -i' to clean up history. (That would break links *unless* the MediaWiki revision IDs somehow stayed constant for the revisions with the same content. Maybe that's feasible. Actually, the simplest way might be to write a tool that filters the dump file itself, rather than exporting straight from git-remote-mediawiki.)
Also also, I fixed a format string bug in git mergetool, one of my favorite little pieces of git.
P.S. In this corpus, of the IP address editors (i.e., not logged in), 0 (of 16) are spammers. About 80% of the logged-in editors are spammers. (Admittedly our wiki does require you to log in if you are posting new URLs to a page.)
Update: It is way faster if you run it with low latency to the MediaWiki server in question. It probably could be adjusted to make fewer API calls, and to make more of them in parallel.
[] permanent link and comments
Sun, 29 Jul 2012
Twisted high scores
Living in the Boston area, I've had the chance to spend time with the lovely maintainers of the Twisted project.
Twisted is an event-driven network programming framework in Python. It's also a community of people for whom software is never good enough -- and they're right.
I visited the Twisted November sprint at the Smarterer.com office a few weeks ago and reviewed a ticket. So now I am on the Twisted high scores list for November!
It was one of the most rewarding short periods of time I've ever spent contributing to an open source project. I took someone's contribution and turned it into a patch, and also gave some feedback. This counted as reviewing a ticket, for which I was immediately and strongly socially rewarded: J.P. (exarkun) turned to me and say, "Thanks for contributing to Twisted."
An IRC bot pinged me with a note saying my ticket review was complete. And now I appear in the high scores list for November!
[] permanent link and comments
RHEL 7 will (probably) have GNOME 3
While chatting with Greg Price earlier this evening about the coming Linpocalypse, I said something I wanted to research. Upon further review, it seems that Red Hat Enterprise Linux 7 will ship GNOME 3.
You can see a video of Jonathan Blandford talking about it, where he says:
And then looking forward to the future, RHEL 7.... We're giving demos of GNOME3, and the new desktop is a huge change; we're doing some pretty exciting things there. So if you're interested in it, please come by and take a look!
"CubedRoot" on fedoraforum.org did take a look, and (s)he wries:
I went down to the Partner Pavillion and spent over an hour with Jonathan and the RHEL7 demo they had running. Besides a new wallpaper (Which was very beautiful BTW) they were running Gnome 3.5 on the demo, an the only other major changes were a few more account service providers and chat plugins (like Sametime, Yahoo, and stuff). It did not handle multi-monitors with different resolutions worth a flip (but it is beta after all). This is when I asked him if they planned on putting XFCE or LXDE or even Cinnamon in the Extra's channel, and they very confidently said they would not be in there. They had no plans to offer them.
[] permanent link and comments
Mon, 06 Jun 2011
How much do I charge?
A conversation between me and a wiser housemate, when I lived in San Francicsco.
Asheesh: "Hey, so I'm going to do some consulting work. It's the first time I've done this as a professional, like, not a student. How much should I be charging per hour?"
Matt: "It's easy; do what I do. Think of the biggest amount you can ask for with a straight face, then double it."
[] permanent link and comments
Sat, 23 Apr 2011
Announcing the Scala Crash Course (for women & their friends)
Here is an email I just sent to the email list for PHASE, the Philly Area Scala Enthusiasts:
First, let me introduce myself: Hi, everybody!
I'm Asheesh Laroia, as the "From:" header on this email message indicates. I'm also a Python user, former ocaml user in college, and Debian developer. (Maybe none of those will make me any friends in PHASE....)
I'm writing this because Yuvi and I are planning an event on the Friday evening before Scalathon: a low-cost Scala crash course.
http://www.meetup.com/scala-phase/events/17397558/ says a little more; I can, too:
My goal (I won't claim to speak for Yuvi) is to help encourage a diverse Scalathon that brings new people into the community. By being a "crash course" for people who already know some Scala or another functional programming language, we aim to select for people who can contribute during the big hackathon on so many Scala projects during the weekend. By insisting that attendees of the crash course attend Scalathon, we hope to use the time to enrich the Scalathon event.
The event has a stipulation that I'm borrowing from an effort called RailsBridge: to attend, you must either be a woman, or find a woman who will bring you as her guest. The idea here is to simultaneously make sure anyone who wants to can attend, while also inviting women to join Scala-based communities.
The event is separate from Scalathon; it's an effort to feed people into Scalathon.
If you are a woman who is thinking about attending Scalathon but wants to make sure you have time to sharpen your Scala chops, this event is for you. If you know such a person, please send her a copy of this email. If you're a man in the same situation, we hope you can find the woman in your life who is, too, so that she can invite you.
So -- that's what I'm working with Yuvi.
A bit more personally, I met Yuvi because I work on an open source community outreach website called OpenHatch: http://openhatch.org/. He and I met at a meet-up for that site last year, when I lived in West Philly (on a beautiful street called Hazel). He and I organized a Penn-based open source hackathon you can read about at http://opensource.com/life/10/11/introducing-students-world-open-source-day-1 . Right now I'm based in the Boston area, in Somerville, MA.
I'd love to hear what you all think.
--
-- Asheesh.
http://asheesh.org/FORTUNE PROVIDES QUESTIONS FOR THE GREAT ANSWERS: #4
A: Go west, young man, go west!
Q: What do wabbits do when they get tiwed of wunning awound?
[] permanent link and comments
Thu, 24 Sep 2009
Award for the best clickable button in a mobile app
I just saw a screenshot of one of my favorite Android apps - at least, as far as user interface design goes.

A simple interface, and a single button that creates a Blue Screen of Death. My compliments to the chef.
(Found via [http://forum.xda-developers.com/showthread.php?t=563891 the XDA-Developers forum. It appears to be a UI-improved version of someone else's vulnerability tester called BSODroid.)
[] permanent link and comments
Sat, 25 Apr 2009
Explainer: "Why do some URLs have www in them, and what difference does it make?"
Katy (who I know from the CC internship in 2006) asked me this question recently:
Why do different pages show up depending on whether there's a www or not in the URL?
To understand, I have to explain how a browser gets a web page from the Internet. When a browser is asked to load a URL like <a href="http://www.asheesh.org/scribble/enlightened-but-confused.html> http://www.asheesh.org/scribble/enlightened-but-confused.html</a>, it breaks it apart into components.
- "http" is the the scheme
- "www.asheesh.org" is the domain name
- /scribble/enlightened-but-confused.html is the path
HTTP, the "scheme", tells the browser what protocol (or network language) to speak when it requests the page from the server.
The domain name is where things get interesting. This alone tells the browser who to ask for the page. The browser looks up www.asheesh.org in the domain name system, an Internet phone book service that converts names to numbers (so-called "IP addresses"). Once it knows the IP address for that name, it connects to it and prepares to speak HTTP.
The browser connects to that IP address, and asks (in the network language of HTTP):
- Hey, I'm trying to get a page from the website called www.asheesh.org.
- Please give me /scribble/enlightened-but-confused.html
So now, let's think about how http://www.asheesh.org/ and http://google.com/ differ: Their scheme is the same, and their path is the same. But the domain name is different.
The same is true for http://asheesh.org/ and http://www.asheesh.org/. You get the same content because, as luck has it, the administrator for asheesh.org is the same as the administrator for www.asheesh.org, and I decided to make them work the same way.
For some websites, if you add the www component, you do get different contents back: for example, http://cs.rochester.edu/ does not load, whereas http://www.cs.rochester.edu/ does.
So the final answer to Katy's question: You're lucky you ever get the same page for two URLs that are different, even if just by "www".
